QnA - K-Nearest Neighbor
This post is a quick revision guide on k-NN. The answers are neither of advanced level nor of the layman level. Some questions require proper answer and will be updated as I better my understanding
What is k-nearest neighbors?
k-NN is a classification technique. It tells as to which class a query point belongs to.
When might k-nearest neighbors fail?
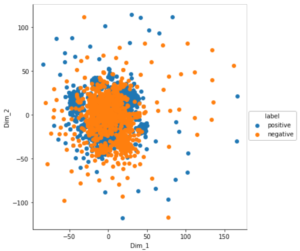
It fails when training data is mixed, that is, there is no way to distinguish between the classes. See the figure below, there is no clear way to distinguish between positive and negative class, hence we cannot say as to which class a query point will belong.
K-NN also fails when the distance of query point is equal from both positive and negative class.
Define Distance measures: Euclidean(L2) , Manhattan(L1), Minkowski, Hamming?
The Minkowski distance is a metric in a normed vector space which can be considered as a generalization of both the Euclidean distance and the Manhattan distance.
Find the equation here in wiki:
In the equation, p=2 would imply Euclidean distance (also known as l2 norm). p=1 would imply Minkowski distance.
Hamming distance is equivalent to the number of locations/dimensions where two binary vectors differ.
What is Cosine Distance & Cosine Similarity?
The cosine of the angle between two vectors is the measure of cosine similarity. More the similarity, lesser is the distance. Mathematically, Cosine Similarity = 1 - Cosine Distance
How to measure the effectiveness of k-NN?
Given a dataset with class labels, we divide the dataset into Dtrain and Dtest. We calculate the value of K on Dtrain. Now with the calculated K value we predict the class label of Dtest. Now to measure effectiveness, we will calculate accuracy on Dtest as-
Accuracy = (Number of points for which Dtrain and KNN gave correct class label)/(Number of points in Dtest)
What is the Limitations of KNN?
Biggest limitation of KNN is its high time and space complexity. If a data point is of d dimensions then for n points in Dtrain, the time complexity of finding the nearest neighbor for each of the n data point is O(nd).
The value of d could be very big depending on the data type. For example, in BOW of Amazon Review Dataset, d = 100K, for tfidf, it is 300K.
How to handle Overfitting and Underfitting in KNN
For K=1, we will have overfitting and for K=n, we will have underfitting. Infact, for K=n, every data point will belong to majority class. Overfitting decision surfaces are non-smooth and less robust (prone to noise). A smooth decision surface neither under-fits nor over-fits. Underfitting occurs in lazy systems. A well balanced system has a smooth decision surface.
Why there is a Need for Cross validation?
The available dataset, D is divided into D-train and D-test. While D-train is used to train the model, D-test is used to evaluate the right value of K. The right K corresponds to the highest accuracy on D-test.
Accuracy on D-test = (Points for which D-train and K-NN gives correct class label)/(Total number of points in Dtest)
This accuracy can be calculated only on D-test .Hence, we calculate accuracy for different values of K, then decide on the right value of K. But, we cannot say that for future data also, this K value would give the highest accuracy. For this problem, we have a concept called as Cross validation. In Cross Validation , the concept is to use D-cv instead of D-test to get the right value of K. So now, the dataset is divided into three disjoint sets which are, D-train, D-test and D-cv.
While D-train is used for training the model, D-cv is used to get the right value of K. D-test is now the unseen (or future) data.
What is K-fold cross validation?
In K-fold cross validation, D-train itself will be used to get the value of K instead of D-cv. The K in K-fold is not the same K as the K in KNN.
In K-fold cross validation, the D-train is divided in K sets of training data and 1 set of cross validation data. (Dtrain split into K+1 set). We calculate the accuracy on different permutations of K sets of training data and 1 set of cross validation data. This is repeated for different values of K (of KNN). We choose the K (of KNN) depending on the highest accuracy. The highest accuracy can be found out, either using majority vote or average of all the permutations.
Advantage: Here we have used the entire Dtrain to calculate K. We have not used Dcv or Dtest. Dtest remains an unseen data. Rule of thumb: Use 10 fold cross validation.
What is Time based splitting?
For time based splitting, data should have a time feature (say timestamp). Whenever time is available and if data changes over time then time based splitting is preferable to random splitting. Dividing the dataset into D-train, D-test and D-cv on basis of time. We have to make sure that the available dataset is sorted on basis of time. After that, we can use the first 60% of data as D-train. Next 15% as D-cv and next 15% as D-test.
Explain k-NN for regression??
In classification, we use majority vote to get the right value of label/class. In regression, we end up getting numerous values for label/class. In such case, we use either mean or median to get the right value of the label/class.
What is weighted k-NN ?
After we evaluate distance between nearest neighbor and the query point, we will give higher weight to closer distances (lower weight to farther distances) and then take the class label on basis of higher weight. Evaluation of weight from the distances can be done so using formula. The simplest formula which can be used is: weight = 1/distance (there could be different formula to calculate the weight).
Sometimes, the class label of a query point under consideration could have been +ve in some cases had we would have taken only majority vote. But, with weighted k-NN, we have a -ve label.
What is Locality sensitive Hashing (LSH)?
Similar to hashing in data structures. In Locality Sensitive Hashing, given a data point x, it computes the hash function on x. The result of hash function on x and its neighbor is such that they all end up in the same bucket in hash table.
Given a query point, we can find its hash function and see as to which bucket it ends up in. By looking at the values of the bucket, we know as to which class/label that query point belongs to.
LSH for cosine similarity?
In LSH for cosine similarity, vectors which are cosine similar will go inside the same bucket in the hash table. [help me in writing this in detail]
LSH for euclidean distance?
In LSH for euclidean distance, vectors which are closer in distance will go inside the same bucket in the hash table. [help me in writing this in detail]